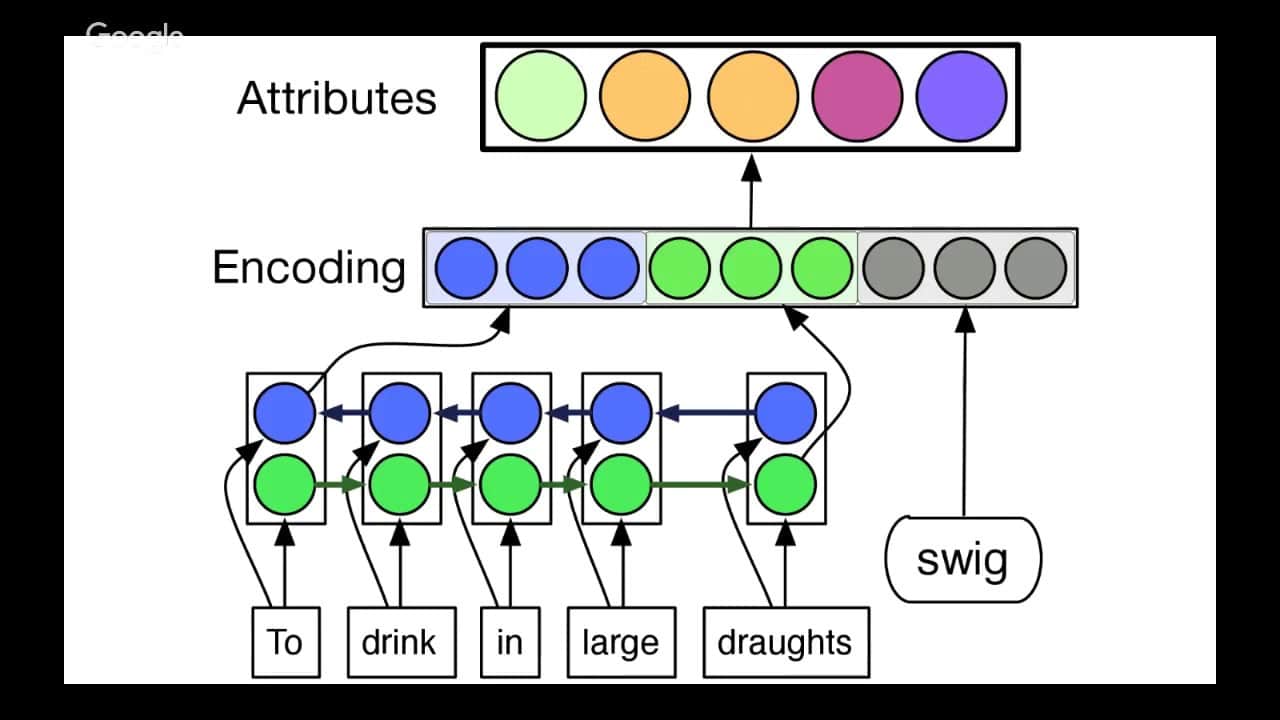
Zero-shot learning (znane również jako zero-training learning lub one-shot learning) to metoda uczenia maszynowego, która nie wykorzystuje etykietowanych danych do szkolenia. Jest wykorzystywana w aplikacjach, w których nie ma dostępnych danych szkoleniowych i może być używana do różnych zadań, od rozpoznawania wizualnego i przetwarzania języka naturalnego po przewidywanie wyników.
Podstawową ideą uczenia zero-shot jest wykorzystanie istniejącej wiedzy modelu (zwykle opartej na zestawie dostarczonych przykładów) do klasyfikowania nowych danych bez konieczności dalszego szkolenia. Model jest wtedy w stanie rozpoznać nowe klasy lub kategorie danych, których wcześniej nie widział.
Na przykład, komputerowy system wizyjny może zostać przeszkolony do rozpoznawania kotów i psów przy użyciu zestawu oznaczonych zdjęć. Po tym, jak model nauczy się rozpoznawać koty i psy, można go następnie zastosować do innych zwierząt, takich jak konie i wielbłądy, bez dodatkowego szkolenia. Jest to możliwe dzięki temu, że model przechowuje informacje o rozpoznawaniu jako funkcję kilku cech, takich jak kształt, rozmiar, kolor futra i inne cechy, które pozostają niezmienne u różnych zwierząt.
Główną zaletą zero-shot learning jest to, że wymaga mniejszej ilości danych do dokładnego przewidywania i może szybko nauczyć się rozpoznawać niewidoczne klasy bez potrzeby korzystania z dodatkowych danych. Jest to szczególnie cenne w dziedzinach, w których zbiory danych są ograniczone lub trudne do zdobycia, takich jak obrazowanie medyczne lub przetwarzanie języka naturalnego. Jednak uczenie bezstrzałowe może być nadal stosowane w szerokim zakresie ustawień.
Metoda ta została z powodzeniem wykorzystana w takich dziedzinach, jak wizja komputerowa i przetwarzanie języka naturalnego, i została rozszerzona na bardziej złożone zadania, takie jak analiza obrazów medycznych, rozpoznawanie twarzy, analiza nastrojów i klasyfikacja obiektów 3D.
Potencjał uczenia zerowego sprawił, że stało się ono popularnym narzędziem w wielu zastosowaniach sztucznej inteligencji. Jest to skuteczny sposób na wykorzystanie ograniczonych zestawów danych i umożliwił wykorzystanie sztucznej inteligencji w obszarach, w których dane mogą być ograniczone lub trudne do zdobycia.