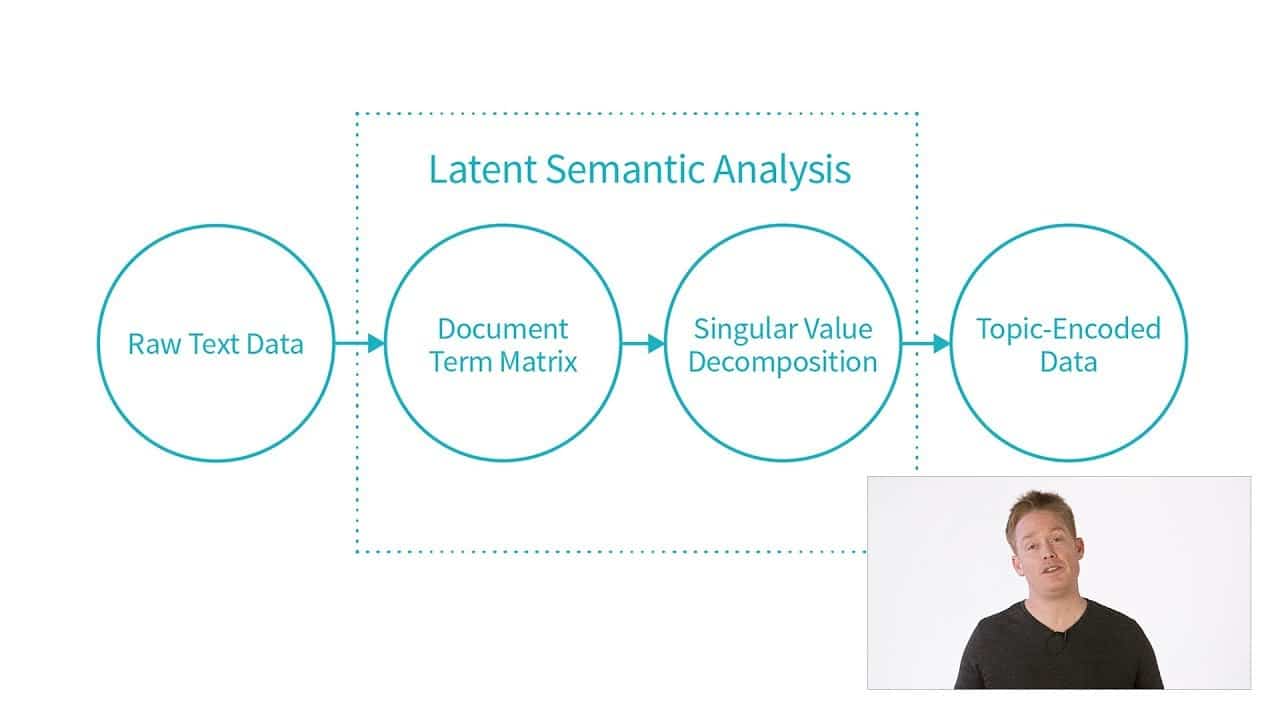
Latent Semantic Analysis (LSA) to technika analizy relacji między słowami w dokumencie tekstowym polegająca na znajdowaniu wzorców w relacjach między słowami. Służy do ilościowego określania i identyfikowania ukrytej struktury semantycznej danego tekstu. Działa poprzez przekształcenie tekstu w strukturę matematyczną, która mierzy relatywność słów w tekście.
LSA opiera się na teorii, że język jest używany do wyrażania znaczenia, a aby zrozumieć tekst, należy wziąć pod uwagę różne sposoby, w jakie słowa są ze sobą powiązane. Zakłada ona, że teksty zawierają podstawową strukturę semantyczną, którą można określić poprzez analizę relacji między słowami. Technika ta została z powodzeniem wykorzystana do analizy dużych tekstów do różnych zastosowań, w tym tłumaczenia maszynowego, wyszukiwania dokumentów i podsumowywania tekstu.
LSA opiera się na założeniu, że słowa powiązane semantycznie będą miały podobne wzorce użycia. Została ona wykorzystana do zidentyfikowania ukrytej struktury semantycznej dokumentów, sklasyfikowania ich zgodnie z tematami, które obejmują, lub do wykrycia, do którego języka należy dokument. Może być również wykorzystywana do pobierania informacji z tekstu po podaniu zapytania.
LSA jest wykorzystywana w wielu aplikacjach, takich jak wyszukiwanie dokumentów, tłumaczenie maszynowe, indeksowanie wyszukiwarek i streszczanie tekstu. Ze względu na swoją zdolność do przechwytywania ukrytej struktury semantycznej dokumentów, może być wykorzystywana do klasyfikowania ich w znaczące kategorie lub do wykrywania mieszanki języków w dokumencie. Może być również wykorzystywana do pobierania informacji z tekstu po zadaniu zapytania.
Jest on najczęściej wykorzystywany w dziedzinie przetwarzania języka naturalnego (NLP) i ma zastosowanie w programowaniu komputerowym, cyberbezpieczeństwie i sztucznej inteligencji. LSA jest potężnym narzędziem do zrozumienia dużych ilości tekstu i jest ważnym elementem analizy tekstu w dzisiejszym cyfrowym świecie.