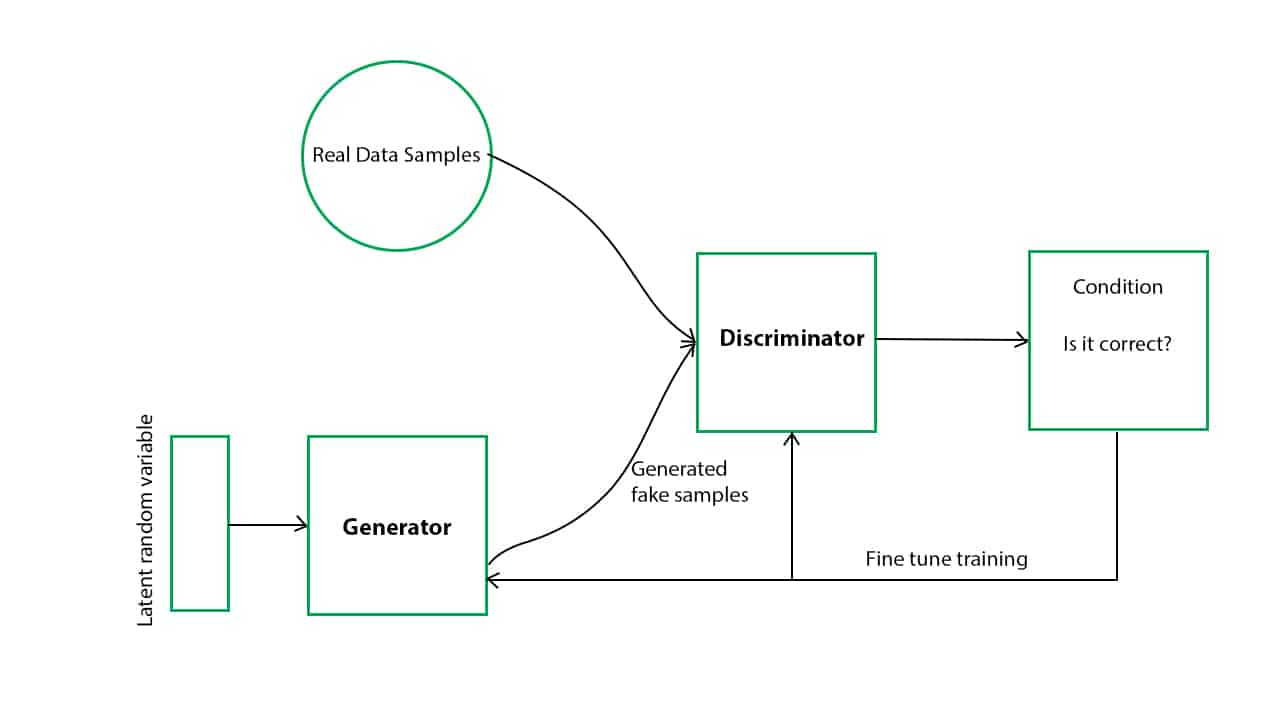
Generative Adversarial Networks (GAN) to specjalna klasa algorytmów sztucznej inteligencji (AI) wykorzystywanych w nienadzorowanym uczeniu maszynowym, zaimplementowana przez system dwóch sieci neuronowych konkurujących ze sobą. GAN składa się z modelu generatywnego, który tworzy syntetyczne dane w oparciu o dane wejściowe, oraz modelu dyskryminacyjnego, który określa, czy wygenerowane dane są prawdziwe, czy nie.
Sieci GAN są wykorzystywane w różnych zastosowaniach, głównie w syntezie obrazu, konwersji tekstu na obraz, analizie wideo, a ostatnio także w pojazdach autonomicznych. Jednym z najpotężniejszych zastosowań jest tworzenie realistycznych obrazów ludzi, obiektów i scen, które w rzeczywistości nie istnieją. Sieci GAN pomagają interpretować złożone wizualnie ustawienia, prowadząc rozpoznawanie obiektów i gestów, a nawet mogą przewidywać przyszłe klatki w treściach wideo.
Sieci GAN zostały po raz pierwszy opracowane w 2014 roku przez informatyków Iana Goodfellowa, Jeana Pouget-Abadie, Mehdiego Mirzę, Binga Xu, Davida Warde-Farleya, Sherjila Ozaira, Aarona Courville'a i Yoshuę Bengio, którzy połączyli modelowanie generatywne z technikami głębokiego uczenia. Jego celem było trenowanie modeli bez etykiet lub nadzoru poprzez posiadanie dwóch konkurujących modeli, które działają jak przeciwnicy.
Model generatywny ma za zadanie lepiej uchwycić rozkład danych w zbiorze treningowym niż jego odpowiednik dyskryminacyjny. Model dyskryminacyjny pobiera próbki z modelu generatywnego i określa, czy są one prawdziwe, czy nie. Oba modele są trenowane równolegle, aby wzajemnie się ulepszać, a oba modele stopniowo poprawiają swoją wydajność, aż osiągną równowagę.
Sieci GAN to potężne narzędzia, które mogą uczyć się złożonych mapowań i generować nowe punkty danych. Wraz z dalszym rozwojem technologii, sieci GAN mogą stać się cennym narzędziem w dziedzinie wizji komputerowej, przetwarzania języka naturalnego, analizy danych i nie tylko.