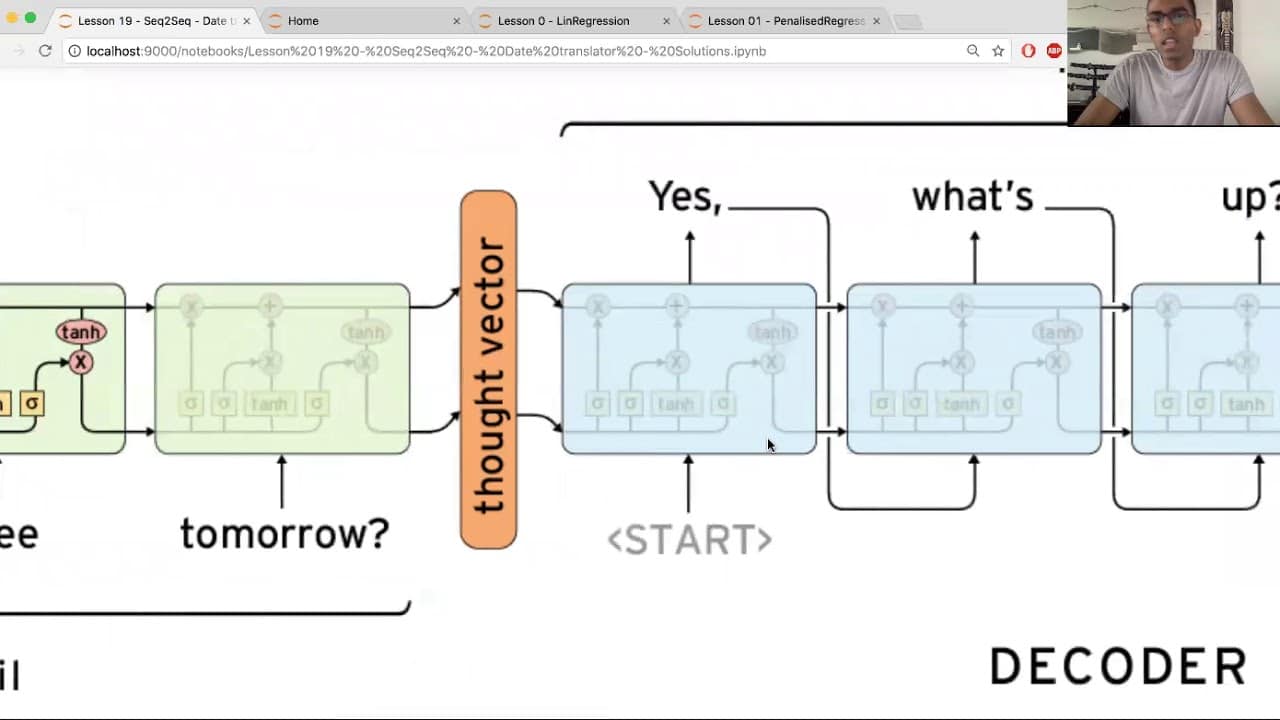
अनुक्रम-से-अनुक्रम मॉडल (Seq2Seq) कृत्रिम बुद्धिमत्ता का एक रूप है जो इनपुट के अनुक्रम (या स्रोत) से आउटपुट के अनुक्रम तक विभिन्न प्रकार के डेटा को संसाधित करता है। Seq2Seq मॉडल का उपयोग प्राकृतिक भाषा प्रसंस्करण (एनएलपी) से लेकर वाक् पहचान तक विभिन्न प्रकार के अनुप्रयोगों में किया जाता है। Seq2Seq मॉडल को शब्दों या वाक्यांशों के एक सेट के साथ प्रस्तुत किया जा सकता है और अनुक्रम में अगले (अगले शब्द या वाक्यांश) की भविष्यवाणी की जा सकती है। Seq2Seq प्रणाली दो भागों से बनी होती है, एनकोडर और डिकोडर। एनकोडर नेटवर्क इनपुट अनुक्रम को इनपुट अनुक्रम का प्रतिनिधित्व करने वाले संख्याओं के एक सेट में परिवर्तित करते हैं, जबकि डिकोडर एन्कोडेड इनपुट अनुक्रम को संसाधित करता है और परिणामस्वरूप अपेक्षित आउटपुट अनुक्रम की भविष्यवाणी करता है। Seq2Seq मॉडल पाठ सारांशीकरण, स्वचालित मशीन अनुवाद और चरित्र-स्तरीय भाषा प्रसंस्करण जैसे कार्यों के लिए उपयोगी हैं।
Seq2Seq मॉडल ने कंप्यूटर, प्रोग्रामिंग और साइबर सुरक्षा के क्षेत्र में कई संभावित अनुप्रयोगों को खोल दिया है। उदाहरण के लिए, इनका उपयोग किसी प्रोग्राम में हमलों को रोकने या संदिग्ध नेटवर्क ट्रैफ़िक का पता लगाने और उसका जवाब देने के लिए स्वचालित रूप से दुर्भावनापूर्ण कोड का पता लगाने के लिए किया जाता है। बुद्धिमान खोज इंजन और प्राकृतिक भाषा उपयोगकर्ता इंटरफ़ेस में उनके संभावित उपयोग के लिए उनका अध्ययन और परीक्षण भी किया जा रहा है। जैसे-जैसे Seq2Seq मॉडल की सटीकता बढ़ती है, यह उम्मीद की जाती है कि प्रोग्रामिंग और साइबर सुरक्षा में विभिन्न अनुप्रयोगों के लिए उनका तेजी से उपयोग किया जाएगा।