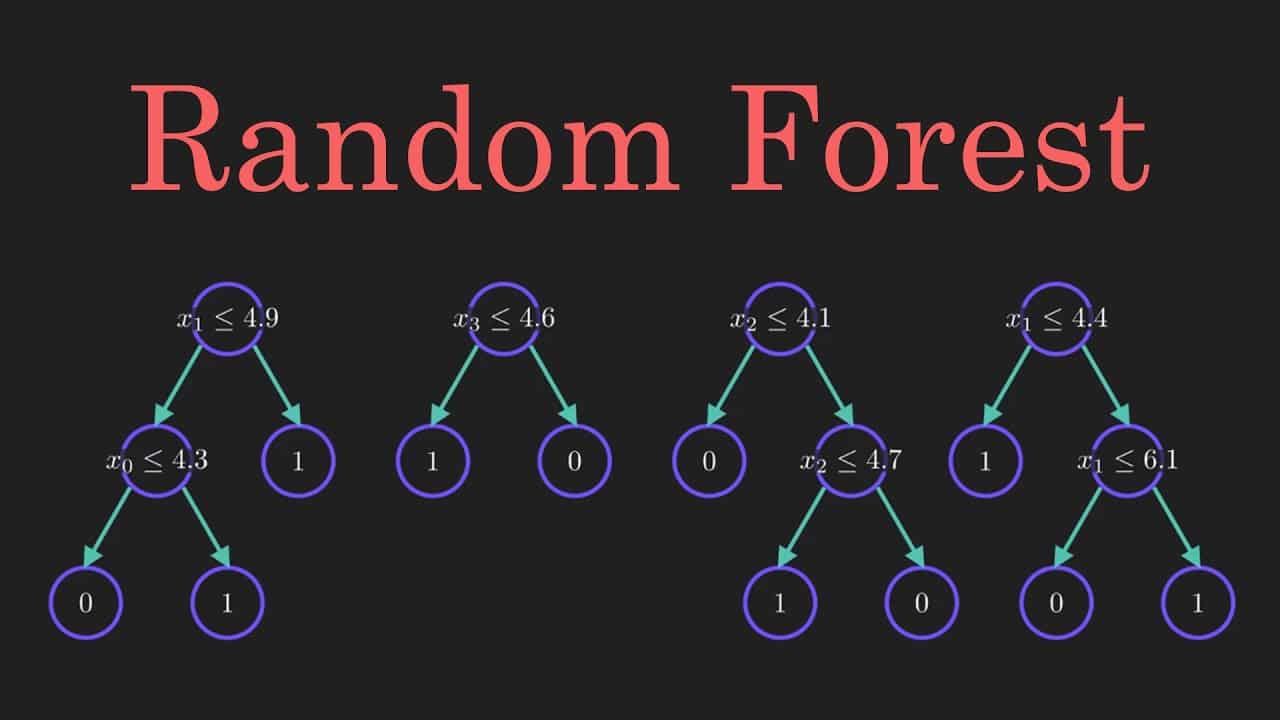
Les forêts aléatoires sont un algorithme d'apprentissage automatique utilisé pour les problèmes de classification et de régression de l'apprentissage supervisé. Il s'agit d'une méthode d'assemblage de plusieurs arbres de décision qui sont formés sur des sous-ensembles aléatoires de données pour une prédiction plus précise et plus stable que les arbres de décision uniques.
L'algorithme a été développé par Leo Breiman et Adele Cutler en 2001. Le mot "aléatoire" dans le nom de Random forests fait référence aux sous-ensembles aléatoires des données d'apprentissage qui sont utilisés pour créer chaque arbre de décision. Il s'agit d'une caractéristique unique parmi les algorithmes d'apprentissage automatique, car les arbres décisionnels utilisent normalement l'ensemble des données d'apprentissage pour faire une prédiction.
Les forêts aléatoires sont un algorithme d'apprentissage supervisé intéressant pour de nombreuses tâches en raison de leur précision, de leur robustesse, de leur capacité à traiter de grands ensembles de données et de la validation croisée des résultats du modèle. L'algorithme produit une moyenne de toutes les prédictions individuelles des multiples arbres de décision de la forêt. L'algorithme a également la capacité de calculer l'importance de chaque caractéristique dans le modèle de prédiction.
En termes de mise en œuvre, les forêts aléatoires sont assez complexes et difficiles à mettre en œuvre. Elles sont intensives en termes de calcul et nécessitent souvent des ressources importantes pour effectuer des prédictions précises. Le réglage des hyperparamètres pour obtenir des performances optimales peut également prendre beaucoup de temps.
Les forêts aléatoires peuvent traiter des données numériques et catégorielles et ont été utilisées dans une grande variété de tâches, y compris, mais sans s'y limiter : problèmes de régression, vision par ordinateur, diagnostic médical, traitement du langage naturel, etc. En général, les forêts aléatoires sont l'algorithme de prédilection pour les problèmes complexes ou les ensembles de données contenant un très grand nombre de caractéristiques.
Dans l'ensemble, Random forests est un algorithme d'apprentissage supervisé facile à utiliser, largement disponible et puissant pour les tâches de classification et de régression. Il est très précis et peut traiter de grands ensembles de données contenant de nombreuses caractéristiques.