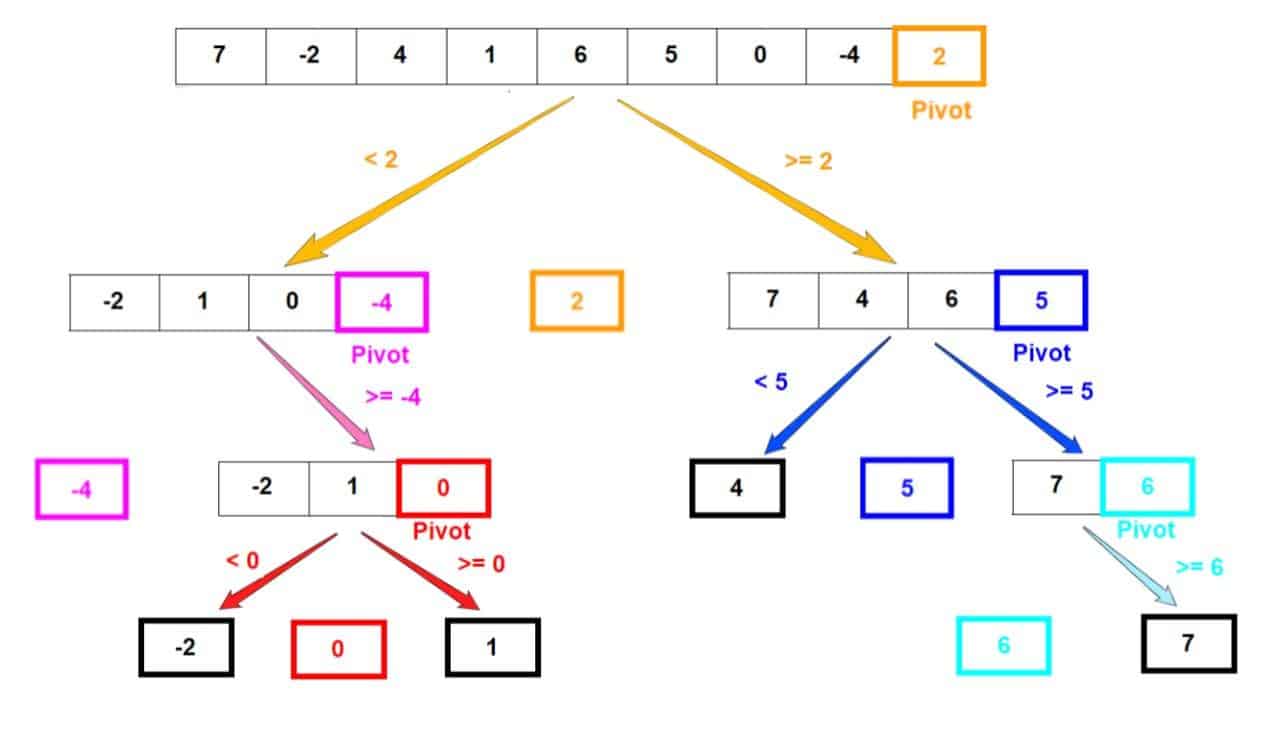
Le tri sélectif est un algorithme de tri efficace, principalement utilisé pour trier de grands ensembles de données. Il s'agit d'un type d'algorithme "diviser pour régner", c'est-à-dire qu'il divise un grand ensemble de données en sous-ensembles, puis traite chaque sous-ensemble afin de trier l'ensemble des données.
L'algorithme de tri sélectif est généralement exprimé en pseudocode :
Quicksort(A, left, right)
si droite > gauche
sélectionner une valeur pivot A[pivot]
partition du tableau autour du pivot
Quicksort(A, left, pivotIndex - 1)
Quicksort(A, pivotIndex +1, right)
L'algorithme de tri sélectif peut être expliqué comme suit. L'algorithme commence par sélectionner un élément, appelé pivot, dans l'ensemble de données utilisé comme élément de partition. Des sous-ensembles de données sont ensuite créés sur la base du pivot, les éléments plus petits que le pivot étant placés dans un sous-ensemble et les éléments plus grands que le pivot étant placés dans un autre. L'algorithme traite ensuite chaque sous-ensemble de manière récursive jusqu'à ce que l'ensemble des données ait été trié.
L'algorithme de tri sélectif est l'un des algorithmes de tri les plus efficaces qui soient, avec une complexité temporelle moyenne de O(N log N). Il est particulièrement utile pour trier de grands ensembles de données, comme ceux que l'on trouve dans les systèmes de bases de données.
En raison de son efficacité, l'algorithme de tri sélectif est utilisé dans de nombreux langages de programmation, notamment Java, C++ et Python. Il est également fréquemment utilisé dans des applications telles que les algorithmes de recherche, le traitement graphique et la cybersécurité.