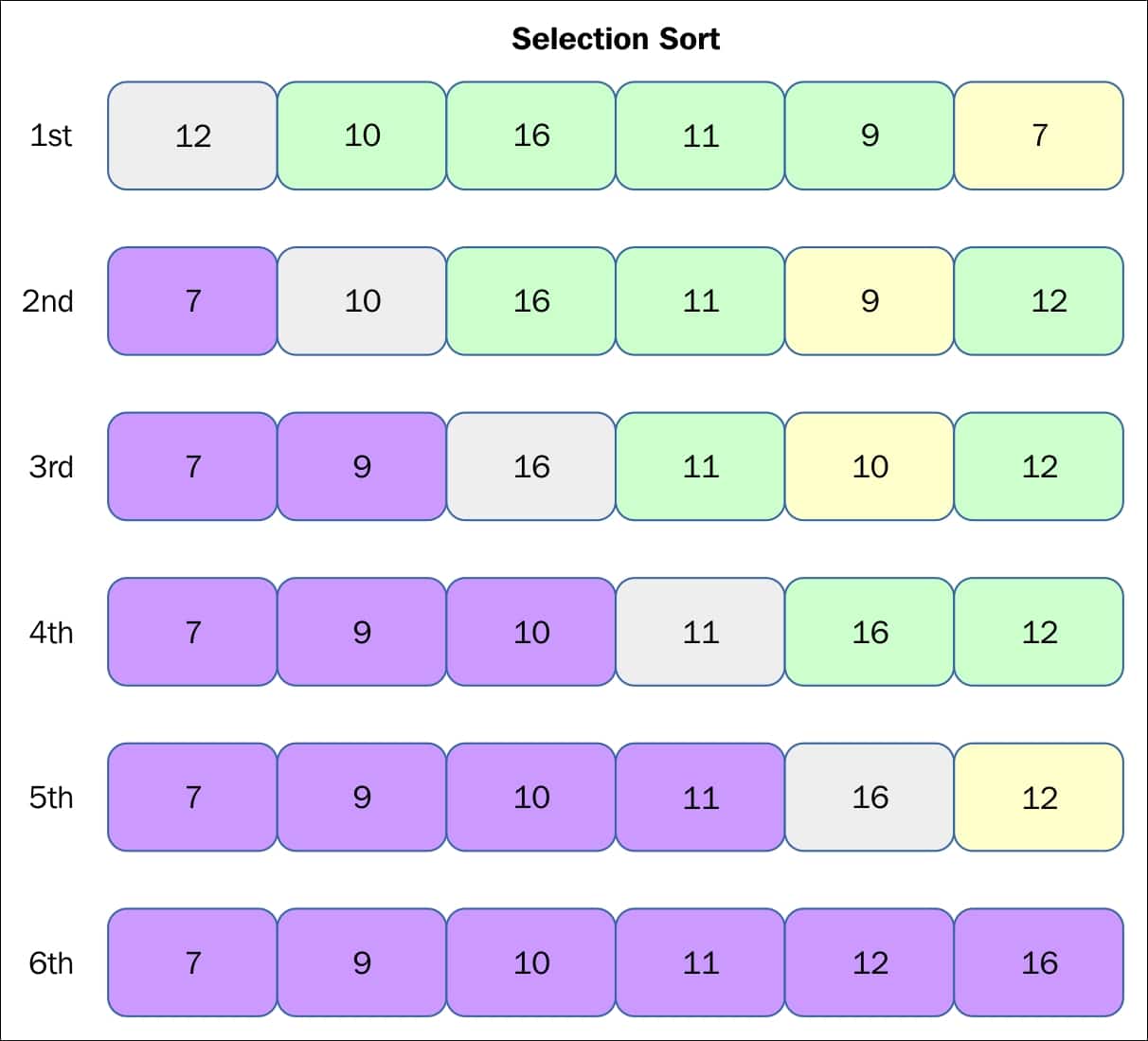
Le tri par sélection est un algorithme de tri souvent utilisé en informatique. Il sélectionne le plus petit (ou le plus grand) élément d'une liste non ordonnée, le place au début (ou à la fin) de la liste, puis répète le processus pour les éléments restants. Au fur et à mesure qu'il progresse, il trie continuellement et construit la liste triée.
Le tri par sélection fonctionne le mieux sur une liste ordonnée de manière aléatoire et a une complexité temporelle de O(n2), ce qui le rend plus lent que certains autres algorithmes de tri. Il est considéré comme un algorithme de tri "sur place", car il ne nécessite pas d'espace supplémentaire pour trier un tableau.
Le tri par sélection peut être un algorithme approprié pour certains types de programmes, mais il ne peut pas être utilisé pour les grands ensembles de données car il est très lent. En outre, il n'est pas très stable, ce qui signifie qu'il peut potentiellement modifier l'ordre relatif des éléments égaux.
Le tri par sélection est utilisé dans des langages de programmation tels que C, C++, Java, Python et JavaScript, entre autres. C'est également l'une des méthodes de tri fondamentales enseignées dans les cours d'introduction à l'informatique.