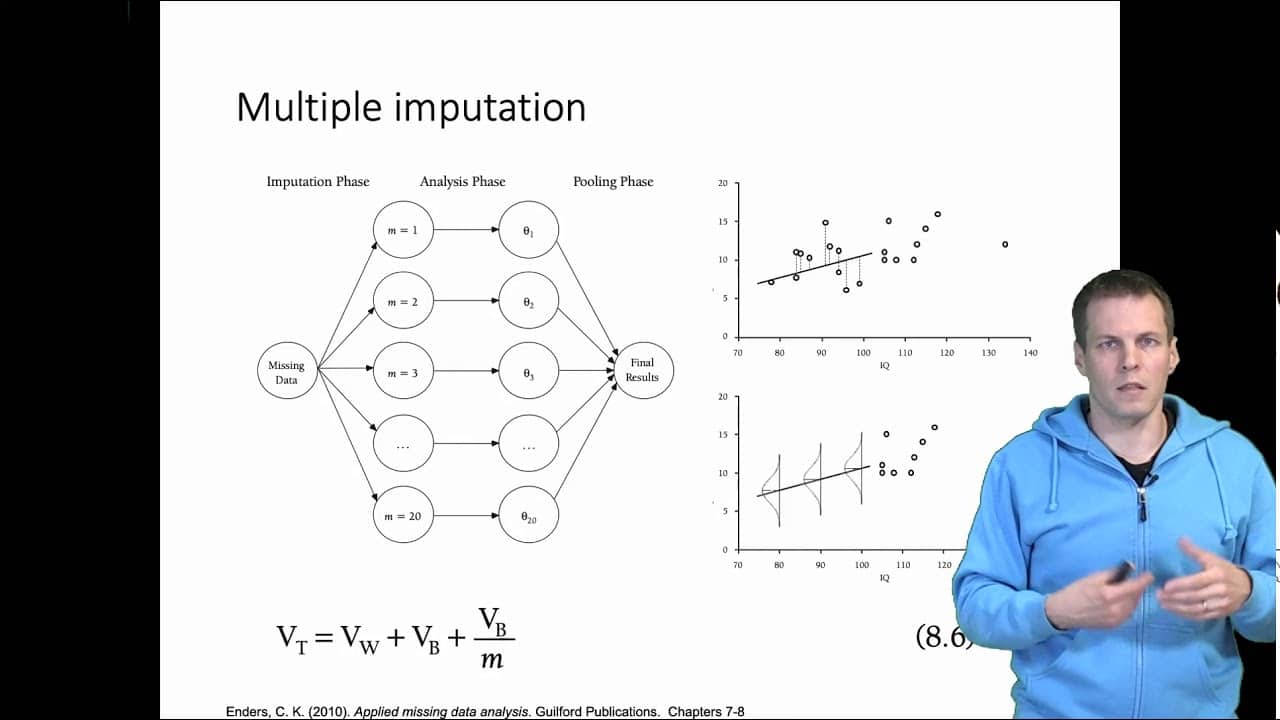
L'imputation des données est une méthode d'analyse statistique qui permet de compléter les données manquantes. Cette technique est utilisée pour remplacer les données manquantes par des valeurs statistiquement estimables qui préservent l'exactitude et l'exhaustivité des ensembles de données. Si l'imputation des données peut être utile, elle présente également le risque d'introduire un biais dans un ensemble de données en raison de l'utilisation d'un petit sous-ensemble de données pour estimer une population plus large.
L'imputation des données est principalement utilisée dans le contexte de l'analyse prédictive, où la disponibilité des données peut être limitée ou incomplète. L'imputation permet d'obtenir des prédictions précises dans le cadre d'un processus d'analyse prédictive. Sans imputation, l'analyse d'un ensemble de données comportant des valeurs manquantes aboutirait probablement à des prédictions inexactes en raison des "trous" dans l'ensemble de données.
L'imputation des données n'est cependant pas toujours idéale. Les valeurs insérées pour remplacer les points de données manquants peuvent produire des résultats incorrects ou trompeurs. Il est donc important d'évaluer le risque de biais avant de supposer que les données imputées sont une représentation valable des données originales qu'elles remplacent.
La méthode la plus couramment utilisée pour l'imputation des données est la substitution de la moyenne. Il s'agit de la forme la plus simple d'imputation, qui consiste à remplacer la valeur manquante par la moyenne de toutes les autres valeurs présentes. D'autres méthodes sont utilisées pour l'imputation, notamment le k-voisinage le plus proche et l'imputation multivariée. La complexité de ces techniques peut varier en fonction de la taille et de la structure de l'ensemble de données en question.
L'imputation des données est essentielle pour garantir que les ensembles de données sont complets lorsque l'on a recours à la modélisation prédictive, mais il est important de mettre en œuvre cette technique de manière responsable. Les ensembles de données doivent faire l'objet d'une vérification approfondie avant que des décisions ne soient prises sur la base des valeurs remplacées. Le cas échéant, il peut être judicieux d'envisager d'autres méthodes, telles que la suppression d'une colonne, ou d'ignorer complètement une prédiction si les données manquantes sont trop importantes ou si les caractéristiques des données ne correspondent pas à la méthode d'imputation employée.